These days I think about collecting data a lot. At Lever we are making software that needs data to function for multiple reasons.
The biggest reason is that data drives the interface, without candidates in it you can’t really do much except for add some data in the form of candidates.
Once you add some candidates you can do things like schedule them for interviews or have people leave feedback on them, which is more data to store and use to present other users with helpful functionality. Even before the candidates and the scheduling, the jobs people can apply for and the stages in the pipeline that they move through are just data in our database. The users of our system and their preferences are data that determine how they use the app and what functionality is helpful, some people just don’t want reminder emails, so we store that data too.
Another way data is important to Lever is because our customers want to understand what is going on with their process, and we can use the data to help them do that. The first and easiest thing we can do is count events.

old reporting interface
In our system whenever an action happens around a candidate, we store what we call a ” profile story.” These stories each can answer four questions we learned in elementary school: who, what, when, and where (sometimes how). Of course this is because sometime after the story happens, someone will want to know why. We record these events so that when we want to reconstruct the history of a candidate to tell their story, we can know who performed actions, when they did it (and how long it took), what actions they performed and where in our app they did it. With this information we can start to look at how many times certain kinds of events take place, we can count how many interviews people are fielding as well as how many people are receiving offers. There are many events to count, but we can also count candidates that meet certain criteria, for example the number of candidates who apply to a certain job or are referred by employees for that same job. There are many ways we can segment our candidates, including by time and how many candidates advanced to particular stages in the pipeline during that time.
Another thing we can do with the data is try to calculate ratios, or changes that occur in the system. By looking at the speed at which candidates move through particular stages, or the number of candidates that move through particular stages we can help people set goals and allocate resources appropriately. If we know that it usually takes 1000 applicants to a particular job to get to 20 on-site interviews in 3 months, and of those 20 interviews only 4 people receive job offers, then we know we have our work cut out for us if we want to hire 5 people for that job. If we also know that it only takes 50 referrals to get to 10 offers, that would inform how we spend our time recruiting. These ratios are different for most jobs, and they even change over time. This means we have to give people more powerful tools to understand how their process works so they can make more meaningful decisions.
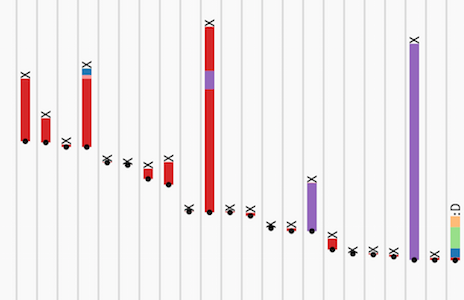
Even though we can calculate fancy derivatives or help people make decisions, we still need to remember that it comes down to the people in the process. Beyond finding patterns, you also want to find outliers. Are there candidates who we’ve let slip through the cracks? Are there very controversial candidates? Behind the numbers for every query, aggregation and calculation are individual people trying to find out if they are a good fit for a company and that company is a good fit for them. We don’t just want to make the patterns and the outliers visible, we think its important that you can find the people behind the numbers.
We know we can only tell the story that we have the data for, and we can only capture the data that encodes the processes people use. We can’t tell the whole story, but we strive to illuminate as much as we can. So as much data as we collect, as much as we try to surface to our users and as much as it drives our app, it doesn’t drive us. The people drive us and we drive the data for them.